
안녕하세요~!
Brightics 서포터즈 2기 정해웅입니다 😀
지난 포스팅에서는
저희 슬기로운 분석 생활 팀 분석 미션인
데이콘 - [신용카드 사용자 연체 예측 AI경진대회]
에 대한 데이터 설명과 전처리, 그리고 모델링까지 보여드렸습니다.
마지막에 Accuracy를 이용한 성능 평가까지 보여드렸는데요.
비록 2등 수상자인 승찬이형의 코드를 기반으로 accuracy를 측정하였을 때

0.738이라는 스코어가 나왔고
저희의 XGBoost Classification 모델의 성능이 0.725까지 나왔기 때문에
Brightics만을 이용해도
python에서 코딩한 것 만큼의 높은 성능을 구현할 수 있다!
라는 결과를 얻었습니다.
그러나 저희 팀은 여기서 멈추지 않고
python을 능가할 수 있는 방법을 생각하게 되었습니다.
바로 "Stacking" 기법입니다.
스태킹 (Stacking) 기법이란,
앙상블 기법 중 하나로 개별 알고리즘이 예측한 데이터를 기반으로 다시 예측하는 기법입니다.
자세한 내용은 조금 뒤에 알아보고
먼저, 저희가 활용한 알고리즘들에 대해 짚어보고
스태킹까지 자세하게 다뤄보겠습니다.
왜 스태킹하면
청하의 스냅핑이 떠오르는 걸까요..?
스냅핑 스냅핑~
스태킹 스태킹~
ㅋㅋ 벌써 중독 됐다~
저만 그런거 아니죠?
이번 포스팅 배경사진에는 특별히 청하느님을 뒤에 깔아봤습니다.
한층 화사해졌네요 ^^7

1. Random Forest (랜덤 포레스트)
랜덤 포레스트는 대표적인 배깅 앙상블 알고리즘으로, 결정 트리를 기반으로 학습합니다.
이 때, 배깅(bagging) 이란 같은 알고리즘으로 여러 개의 분류기를 만들어 보팅으로 최종 결정하며,
서로 다른 알고리즘을 만들어 결합하는 보팅과 비교됩니다.

출처: “파이썬 머신러닝 완벽 가이드”, 위키북스, 권철민 지음
위 사진과 같이 데이터와 피처를 랜덤하게 뽑아 여러 개의 트리를 학습하여서
랜덤 포레스트라고 부른다는 것을 알 수 있습니다.
일반적인 앙상블 알고리즘과 비교해 학습 시간이 짧은 장점이 있으며,
단일 모델에 비해 높은 성능을 보이는 가벼운 형태의 앙상블 알고리즘입니다.
2. XGBoost (eXtra Gradient Boost)
XGBoost는 트리 기반 앙상블 알고리즘 중 각광받고 있는 알고리즘으로,
캐글 경연 대회에서 입상한 많은 데이터 과학자가 XGBoost를 사용하여 널리 알려졌습니다.
이 때, 부스팅 기법이란
앙상블 학습 방법의 일종으로 먼저 모델을 학습하고 예측한 결과를 바탕으로 가중치를 부여하여 재학습하고
각 단계에서 구성된 모델을 결합하여 최종 예측하는 기법을 의미합니다.

출처: “파이썬 머신러닝 완벽 가이드”, 위키북스, 권철민 지음
부스팅 기법 중
GBM에 대해 간단하게 설명드리자면
트리 기반 부스팅 알고리즘으로, 가중치 업데이트를 경사하강법(Gradient Decent)을 이용해 수행하는 것을 의미합니다.
(경사 하강법은 머신러닝, 특히 딥러닝에서 모델 학습을 위해 사용되는 방법)
(성능은 좋지만, 실행시간이 김)
XGBoost는 GBM의 단점을 보완하고자 나왔습니다.
이는 GBM 기반이지만 낮은 수행 시간 문제, 오버 피팅 문제 등을 일부 해결하여 성능 향상시켰습니다.
그러나 XGBoost에도 여전히 문제가 있는데요.
바로 "여전히 느리다"는 것입니다.
GBM보다는 빠르지만, 여전히 여러 하이퍼파라미터의 조합을 튜닝하기엔 느린데요.
이래서 나온 것이 바로 LGBM입니다.
LGBM은 트리의 균형을 맞추지 않기 때문에 XGB에 비해 빠른 속도를 보여주는데
저희 프로젝트에서는 다루지 않기 때문에 생략하겠습니다.
(Brightics에는 LGBM 알고리즘 함수를 보유하고 있지 않습니다.)
저희 이번 분석 프로젝트에서는
Random Forest, XGBoost
위 두 가지 알고리즘을 활용하여
사용자의 연체 가능성을 예측하였습니다.


애초에 전처리를 피처셋 1과 2로 나누어서 진행하였기 때문에
이렇게 Brightics 내에서도 두 가지로 또 나뉜 것을 알 수 있습니다.
따라서 총 4개의 분류 결과가 나왔습니다.
그렇다면 여기서 더 성능을 높이려면 어떻게 해야할까요?
이러한 데이터 분석 대회에서 조금이라도 성능을 높이기 위해 나온 것이 바로
"Stacking" 스태킹 기법입니다.
3. 스태킹 (Stacking)

출처: “파이썬 머신러닝 완벽 가이드”, 위키북스, 권철민 지음
앞서 말씀드렸다시피
스태킹 (Stacking) 기법이란,
앙상블 기법 중 하나로 개별 알고리즘이 예측한 데이터를 기반으로 다시 예측하는 기법입니다.
위 사진에서 나오듯
base learner로 개별 알고리즘을 이용하여 예측을 하고
meta learner로 하나의 모델을 선정하여 그 예측 데이터를 기반으로 다시 예측합니다.
이 때 Meta learner도 학습이 이루어지기 때문에, 배깅/보스팅에서의 보팅과 구분됩니다.
스태킹은 특히 캐글이나 데이콘과 같은 데이터 분석 대회에서
조금이라도 성능을 높여야할 때 자주 사용되는 기법입니다.

출처: “파이썬 머신러닝 완벽 가이드”, 위키북스, 권철민 지음
위 사진을 보면 정말 쉽게 Stacking의 구조를 파악할 수 있습니다.
그렇다면 저희 Brightics 스튜디오에서는
Stacking 방법을 어떻게 활용할 수 있었을까요?
그리고 실제로 성능이 개선이 될까요?!
4. 스태킹 (Stacking) in Brightics
Brightics 에서 스태킹을 하기 위해선
기존 모델링을 통해 나온
라벨에 따른 확률 값들을 하나로 모으는 작업이 먼저 필요합니다.
먼저 랜덤 포레스트를 예를 들면

XGBoost에서는
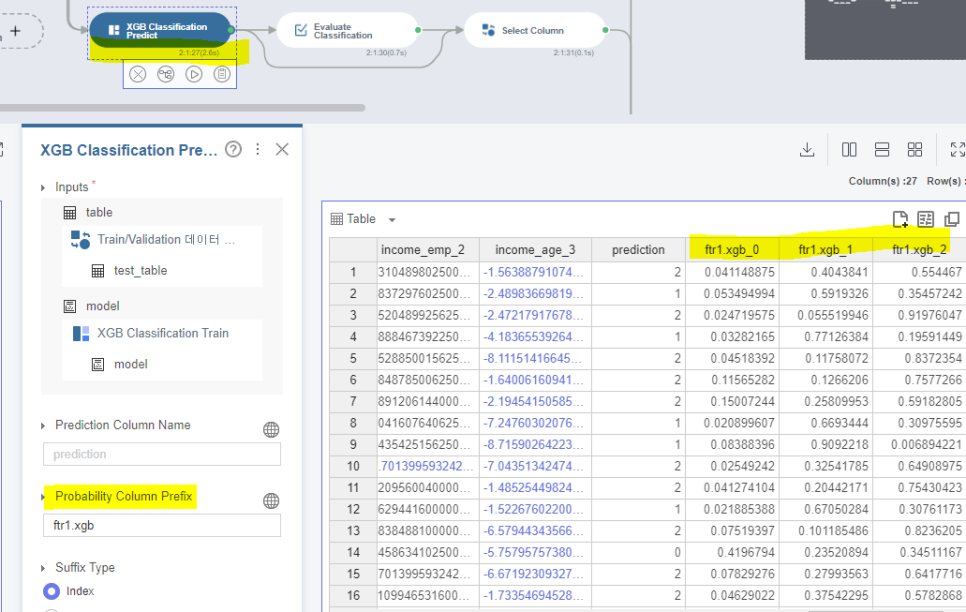
이렇게 prediction을 어떤 숫자 (0,1,2 중)를 택할 지에 대한
확률을 나타내는 probability를 뽑아내는 작업이 필요합니다.
(1) Select Column

위는 피처셋 1의 랜덤 포레스트 결과에 대한 probability만을 뽑아내는 select column 작업입니다.
동일하게 피처셋 1의 XGB
피처셋 2의 랜덤 포레스트
피처셋 2의 XGB
에 대한 Probability를 Select Column을 수행합니다.
(2) Bind Row Column

이후 뽑아낸 알고리즘 당 3개의 probability 그리고 기존 사용자의 대금 연체 정도인 credit 열을 합치는 작업입니다.
(3) 재학습

어느 정도의 전처리 과정을 거친 후,
이 확률값들과 credit을 기반으로 다시 모델링을 하게 됩니다.
동일하게 meta learner로도 랜덤 포레스트와 XGB를 사용합니다.
결과가 궁금하지 않으신가요..?
랜덤 포레스트만 보여드리자면

credit을 제외한 column으로 학습을 시켰고

동일하게 prediction으로 예측값을 선정하게 되었습니다.
(4) 모델 평가


그 결과로
Random Forest를 사용하여 스태킹한 결과 Accuracy : 0.7989
XGB를 사용하여 스태킹한 결과 Accuracy : 0.7885
로 스태킹 전에 나온 XGB accuracy 0.725 와는 꽤 많은 차이가 나타나는 것을 확인할 수 있었습니다.
스태킹을 이용하여 성능이 눈에 띄게 올라가니
정말 신기하지 않나요?! ㅎㅎㅎ
(5) Stacking 알고리즘 참고
저희 멘토님께서 Stacking에 관해서 새로운 알고리즘을 알려주셔서
잠깐 소개하고자 합니다.
Journal of Computers의 <Scaling Up the Accuracy of Decision-Tree Classifiers: A Naive-Bayes Combination>
이라는 논문입니다.
논문의 기본 Concept는 Stack에서 합칠때 각 알고리즘의 정확도 곱하기 각 Class별 확률로 계산하여 구합니다.
즉 A와 B 알고리즘을 사용하면
{A알고리즘 정확도*(A알고리즘에서 Class i 확률)+B알고리즘 정확도*(B알고리즘에서 Class i 확률)}/(A알고리즘 정확도+B알고리즘 정확도)
각 Class 확률 구하는 접근입니다.
정확도와 확률을 기반으로 stacking해서 기존에 알던 방식과는 조금 차이가 있는 것 같아서
팀원들끼리도 멘토님의 자료를 보면서 신기하게 생각했습니다.

Brightics 로 구현한 모델까지 보내주셨는데,
오류를 먼저 잡아보고 저희 모델에 적용시켜봐야겠습니다..!
과연 이 방식으로 stacking하면 어느 정도 성능이 개선될지 궁금하네요 😀
어떠신가요?
Brightics를 이용하여 데이터 전처리부터 시작해서
모델링, 평가, Stacking 까지..!
어렵지 않게 따라올 수 있지 않으셨나요?
이렇게 코린이, 코딩 초보자도 쉽게 데이터 분석을 마치고
성능까지 개선시킬 수 있는 장족의 발전을 이뤘습니다 ㅎㅎ
파이썬과 비교를 하자면
확실히 시각화된 툴이기 때문에
그 데이터가 처리되는 흐름을 한 눈에 파악할 수 있다는 것이 큰 장점인 것 같습니다.
코딩을 하다보면 전체적인 흐름을 파악하기 어려운 경우가 많죠..
또, 이번 프로젝트를 하면서
팀원들간의 Brightics 프로젝트 공유도 참 간편하다는 것을 느끼게 되었습니다.
json 파일로 export하여
프로젝트를 import 하고, 복사하여 합치기만 하면 바로 공유가 되니
함께 협업할 때도 정말 편해서 좋았습니다 ‼
마지막으로 Brightics AI에서 제공되는
Auto Regression이나 Auto Classification과 같이
자동으로 적합한 알고리즘을 찾아주는 함수는 정말 유용한 것 같습니다.
아직 성능이 완전하진 않은 것 같지만, 더 발전한다면 아주 꿀같은 기능이 될 것 같아요.
python으로 하다보면 여러 가지 모델의 라이브러리를 import하는 것부터 시작해서
모델링하고 파라미터를 조정하고 평가하여 가장 성능이 잘나오는 모델을 찾다보면
일단 시간이 정말 오래걸려서 지치게 되는데
Brightics AI의 알고리즘을 찾아주는 기능이 있다면
단시간에 최적의 알고리즘과 파라미터를 제공해주니 이보다 좋은 기능이 어딨을까 싶습니다..
이렇게 stacking까지 해서
팀 분석 프로젝트가 마무리 되었고,
다음은 프로젝트 내용을 기반으로 촬영을 하게 되었습니다.
이번 촬영 미션을 조금 스포하자면

(얼굴 매너해드렸습니다..)
하핫 이번 영상도 기대되네요 🤣
<구해줘 분석>도 많이 기대해주셨으면 좋겠습니다.
그럼 다음에는 촬영 포스팅으로 만나요!!!
* Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS #브라이틱스 #브라이틱스서포터즈 #AI #분석플랫폼 #분석프로그램 #데이터분석 #빅데이터 #인공지능 #SamsungSDS #초보자분석 #분석초보 #코딩 #코딩초보 #통계 #데이터사이언스 #Python #R #SQL #Scala #분석툴 #BrighticsAI #BrighticsStudio #브라이틱스스튜디오 #Brightics #대외활동 #대학생 #대학생대외활동 #삼성SDSBrightics #모델링