
안녕하세요~~!
Brightics 서포터즈 2기 정해웅입니다 💙
지난 주 프로젝트 주제를 선정한 것 기억나시나요?
저희 [슬기로운 분석생활] 팀은
데이콘 - [신용카드 사용자 연체 예측 AI경진대회]
를 나가기로 했었습니다.
이번 주는 팀원들과 함께
참고할 데이콘의 자료를 선정하고
팀을 나누어 높은 평가점수를 받게 분석하였습니다.
과연 Brightics Studio를 활용하여 분석한 결과가
얼만큼의 성능을 보일까요?

귀여운 우리덜,,,
혜현이는 귀신빙의..
1. 참고자료 선정
처음부터 끝까지 분석하기보다는
데이콘 우승자 또는 수상권 사람들의 코드를 참고하고
이를 기반으로 Brightics로 구현하고
그 성능을 확인하는 것을 우선으로 하였습니다.
저희 [슬기로운 분석생활] 팀의 얼굴을 맡고 있는
승찬형님께서는 사실 이 대회의 수상자였습니다.

귀여운 하마 보이시나요? (형 진짜 하마 닮음,,)
데이콘 수상자의 시선에서 바라본다면,
python을 활용한 분석과
Brightics를 활용한 분석의 차이점을 분명하게 볼 수 있을 것 같다는 것도
이 주제를 선정한 이유 중 하나입니다.
https://dacon.io/competitions/official/235713/codeshare/2788?page=1&dtype=recent
Private 3위, Private 0.65913, Stacking Ensemble
신용카드 사용자 연체 예측 AI 경진대회
dacon.io
저는 승찬이형의 3위 코드를 참고하며
Brightics로 분석을 진행했습니다.
이미 형이 대회를 참가하며 시행착오를 겪으며 자세하게 분석을 진행했었기에
막히는 부분이 나오거나, 이해가 안되는 결과가 나올 때 많이 물어보며 진행했습니다.
코드는 feature set 1과 2로 나뉘는데,
저는 feature set 1을 기반으로 분석을 진행했습니다.
2. 데이터 살펴보기
(1) Load
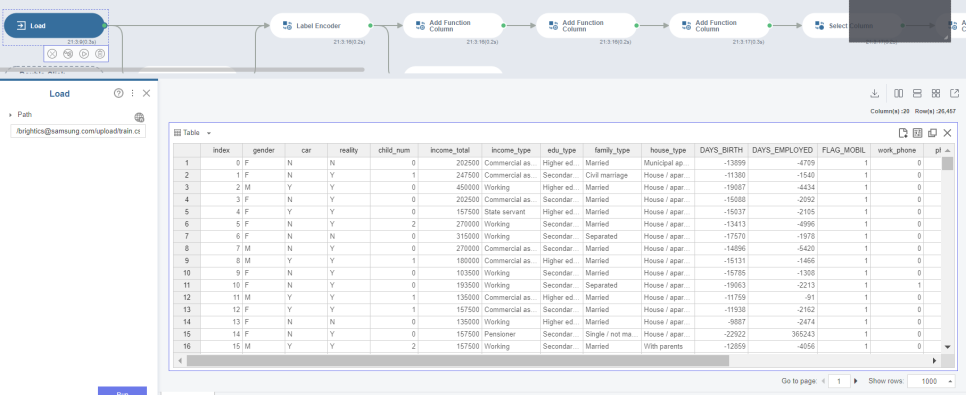
데이터를 Local에서 Load하는 방법은 전 게시물에서 수차례 언급했기에
혹시라도 과정이 궁금하신 분들은 제 앞 포스트들을 참고해주시면 감사하겠습니다 😀
데이터를 Load하고 살펴보니
첫번째 column인 index를 제외하고 19개의 column을 보유하고 있습니다.
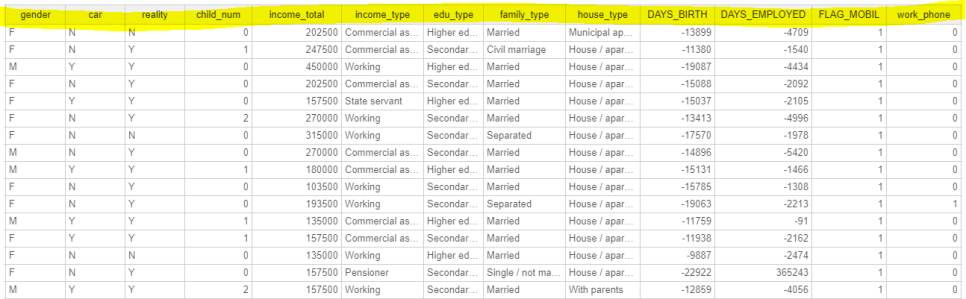
성별부터 시작해서 차 보유, 부동산 여부, 자식 수, 수입, 직업 등 여러 개의 column이
string, int 등 다양한 형태로 분포하고 있는 것을 파악할 수 있습니다.

마지막 column이 바로 저희가 예측해야할 타겟인 credit 입니다.
이것이 바로 사용자의 신용카드 대금 연체를 기준으로 한 신용도를 나타냅니다.
아무래도 카드회사나 보험회사, 은행 등에서 활용 중인 고객들의 '마이데이터'를 사용하여
이런 식의 분석 프로젝트를 진행하고
사용자의 대금 연체 정도를 예측할 수 있다면
회사 입장에서는 굉장한 도움이 되겠죠?
예측 내용을 기반으로
대금 연체 가능성이 높은 고객에게는 카드 한도를 낮춘다거나
대금 납부에 관한 잦은 메세지/알람 을 준다는 식의 활용 형태를 보일 수 있을 것입니다.
(2) Profile Table
해붕's pick Brightics의 자랑거리 중 하나인
Profile Table 기능을 활용하여
데이터의 전반적인 분포를 살펴보겠습니다.
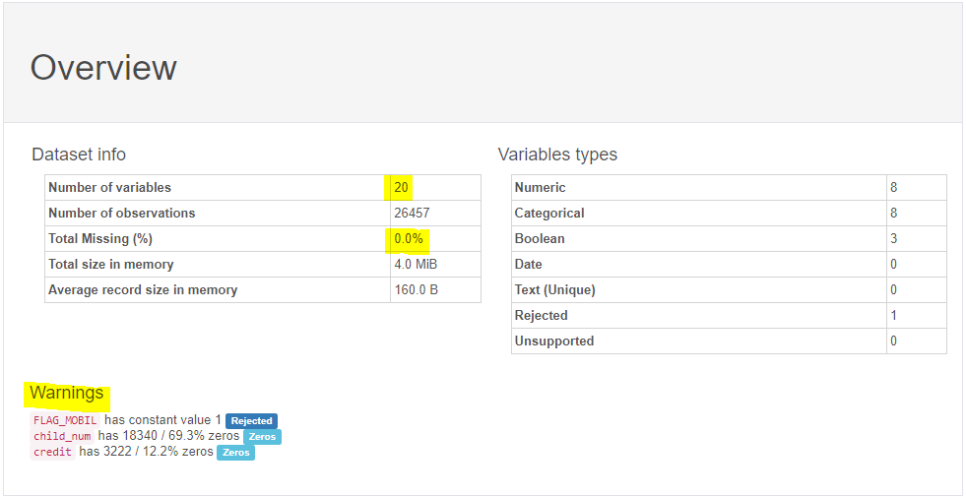
Number of Variables : 20개 (총 column 갯수 20개)
Total Missing : 0% (실제론 직업에서 결측치를 확인할 수 있으나 0%라고 뜹니다.)
Variables types를 통해 열의 타입을 확인할 수 있고
Warnings를 보시면
FLAG_MOBIL이 하나의 값(1)만을 가지고 있다 -> Rejected
Child_num이 69.3%의 zero를 가지고 있다. -> Zeros
credit이 12.2%의 zero를 가지고 있다 -> Zeros
처럼 전처리 과정에 있어 tip이 될만한 요소들까지 분석해서 보여줍니다.
데이터를 한 눈에 파악할 수 있으니
너무 유용해보이지 않나요?!
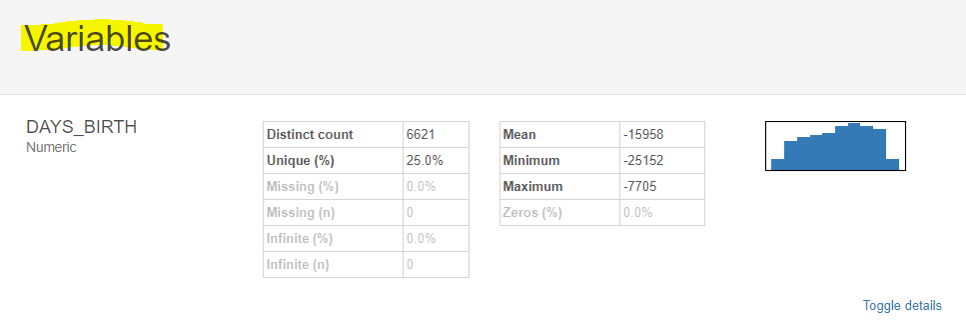

또한 변수 각각의 평균, Min, Max
그리고 사분위 통계, 히스토그램 등 구체적인 요소까지 파악할 수 있습니다.
마지막으로
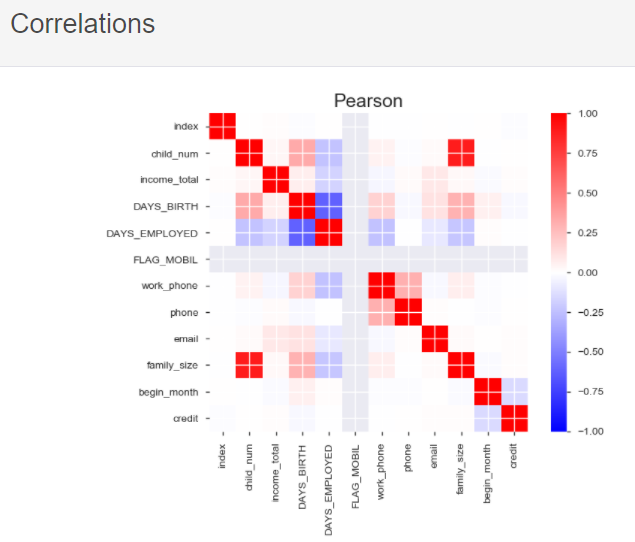

Pearson, Spearman 기법을 활용하여 변수들 간의 상관관계까지
손 쉽게 파악할 수 있답니다 ! (놀라워,, ㄴOㄱ)
하나만 살펴보자면
Pearson과 Spearman 두 가지 기법에서 모두
child_num과 family_size의 상관성이 거의 1로 굉장히 높은 상관성을 보이는데요,
이는 가족의 크기와 자식의 숫자, 어찌보면 당연히 상관성이 높을 수 밖에 없는 변수입니다.
3. 데이터 전처리
데이터의 전체적인 분포를 파악했다면
이제 전처리하는 과정에 들어가게 됩니다.
가장 먼저 할 일은 바로 문자열인 범주형 데이터를 수치형 데이터로 변환하는 작업입니다.

범주형,수치형,이상형,연속형,명목형,순서형 정리
출처: KQTI 오늘은 기본적인 데이터의 종류에 대해서 알아보도록 하겠습니다. 데이터의 종류를 알아보는 것은 데이터 수집시 어떤 유형으로 수집하는 것이 좋은지를 설정하는 것부터 분석이나
horae.tistory.com
Brightics에는 Label Encoder 와 One Hot Encoder 이렇게 두 가지 알고리즘이 있습니다.
저희 멘토님께서 이에 대해 친절하게 설명해주셨는데요


간단하게 요약하자면
One Hot Encoder : 0과 1로 이루어진 칼럼을 여러 개 추가
Label Encoder : 0~N-1로 이루어진 1개 칼럼 추가
라고 볼 수 있습니다.
정확히 구분하지 못하던 개념이였는데, 멘토님 덕분에 개념을 확실하게 잡아가는 것 같아 항상 감사드립니다 😊
또, 알고리즘 별로 권장하는 처리 방법이 있습니다.
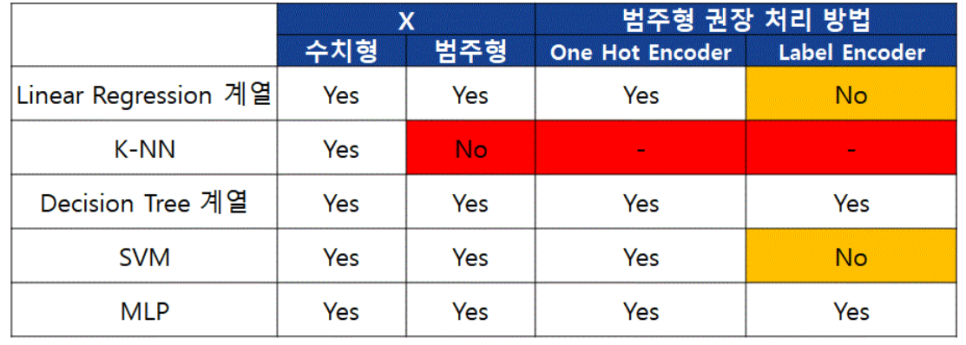
사실 저는 범주형은 수치형으로 바꾸기만 하면 된다고 생각했는데,
알고리즘 별로 One hot을 쓸건지 Label을 써야 하는지 어느 정도 정해져있다니 신기했습니다..!
저희는 Decision Tree 계열로 분석할 예정이라 둘 중 어느 것을 써도 상관없지만
그 중 Label Encoder를 사용하였습니다.
(1) Label Encoder
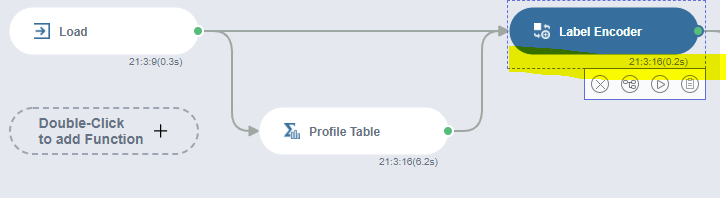
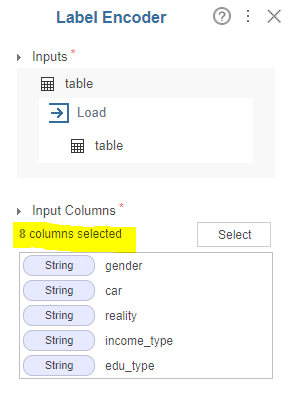
Label Encoder를 통해 gender, car 등 범주형 자료 8개를 수치형으로 변환하였습니다.
Suffix : _index 를 통해 변환 뒤 column을 기존 데이터 + _index로 나타내었습니다.
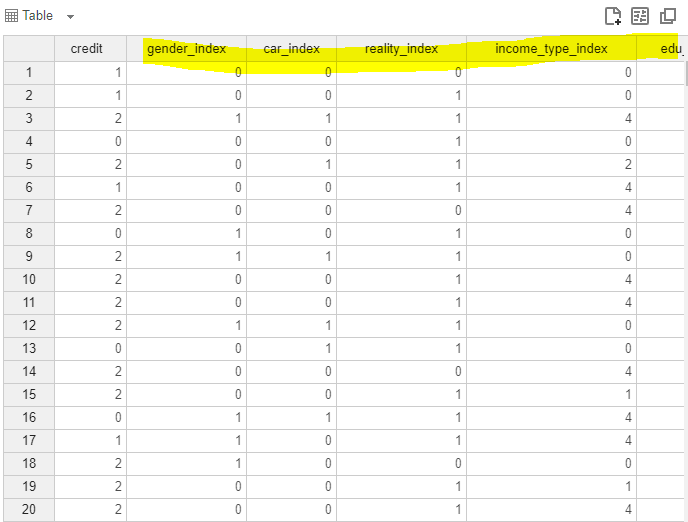
이렇게 새로운 8개의 column들이 수치형 변수로 새롭게 추가된 것이 보이시죠?
(2) Replace Missing Number

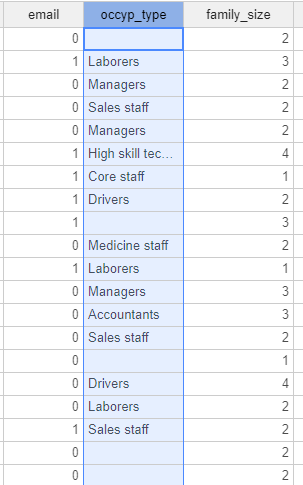
Occyp_type 처럼 직업이 없는 경우 결측치로 해당 되기에
Replace Missing number를 통해 0으로 채워주려고 했으나
Label Encoder를 통해 나온 index 들은 애초에 결측치가 0으로 채워져서 변환됩니다.
또한 이 함수는 str 계열이 아닌 이름에서도 볼 수 있듯이 Missing 'Number'를 채우는 것이기에
저는 이 함수를 사용하지 않고 진행했습니다.
(3) Add Function Columns
이제 성능을 높이기 위한 본격적인 Column 추가 과정입니다.

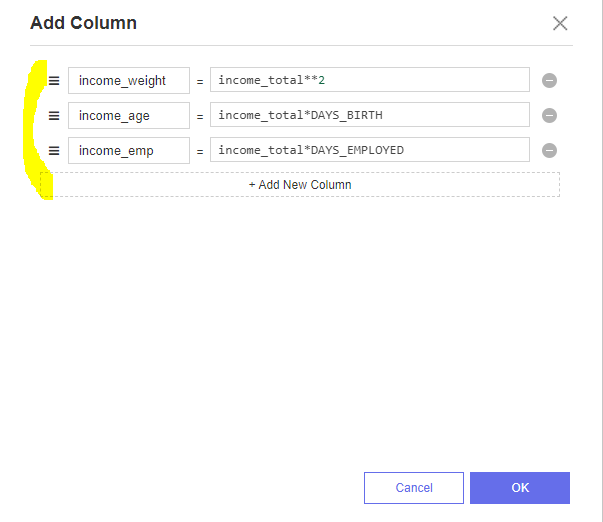
Add Function Columns를 활용하여
income_weight : income_total **2 등 여러 파생 변수를 만드는 과정입니다.
위는 Add Function 'Columns' 가 아닌 'Column'을 써서 위 세 개의 파생변수를 만들었었는데요....
바보같이 한 번에 처리하면 되는 것을 하나하나 일일이 하고 있었네욥 (ToT)/~~~
또 하나 배운다,,,,
(4) Select Column
이제 필요없다고 생각되는 Column을 버리는 단계입니다.
기존 31개의 column -> 28개의 column으로
3개의 column을 버렸는데요.
바로 index, work_phone, family_size 열을 버렸습니다.
work_phone과 family_size는 위의 Pearson, Spearman 상관도 분석에서 보셨다시피
phone과 child_num과 강한 연관성을 보이는 것을 확인했으므로
이 두개의 열을 버리고 나머지 두 개의 열만으로도 분석이 충분히 가능하기에 버리게 되었습니다.
이처럼 데이터 전처리에 들어가기 앞서 데이터의 전체적인 분포를 파악하는 것이 왜 중요한 지 알려주는 대목인 것 같습니다.
(5) Add Function Columns
위 (3)번과 마찬가지로 파생 변수를 생성해줍니다.

이렇게 5개의 변수를 수정 및 생성해주었는데요.
3,4 번처럼 기존 변수를 수정하는 과정을 거치거나
1,2,5 번처럼 새로운 변수를 설정하였습니다.
(6) Split Data


드디어 모델링에 들어가기 전 마지막 단계인 Split Data입니다.
저는 train : test를 7 : 3으로 나누었습니다.
4. 모델링
드디어 대망의 모델링 단계까지 왔습니다.
원래는 팀원들끼리 나누어 모델링을 하려고 했었는데,
Catboost나 LGBM 같은 모델을 Brightics에서 제공하고 있지는 않아서
저는 XGBoost와 Random Forest
그리고 Brightics AI에서 제공해주는 최적화된 함수 찾아주는
Auto Classification 까지 사용해보았습니다.
(1) XGB Classification
가장 먼저 XGB Classification을 이용한 모델링을 진행했습니다.
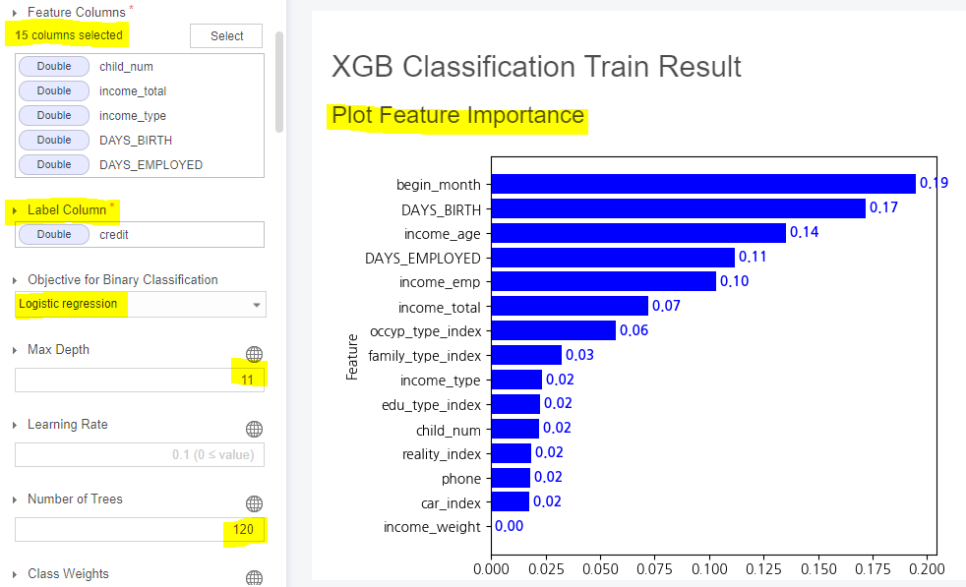
- Feature Column : Feature Importance를 고려하며 최고의 성능이 나오는 feature들을 선정하였습니다.
- Label Column : Credit
- Objective for Binary Classification : Logistic Regression
- Max Depth : 11
- Number of Trees : 120
이렇게 파라미터를 설정하였고

Accuracy : 0.7144
로 꽤 준수한 성능을 보여주었습니다.
참고로
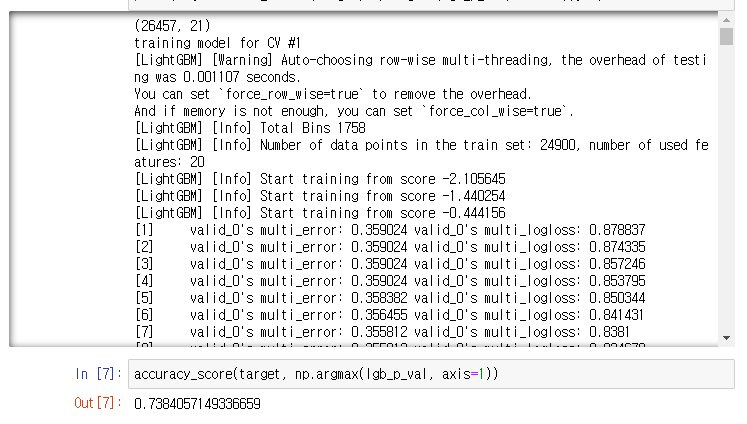
승찬이형의 python 코드에서 accuracy score를 계산했을 때 0.7384이였던 것을 고려하면
크게 차이가 안나는 수준이라고 할 수 있습니다.
(2) Auto Classification

말 그대로 최적화된 알고리즘과 파라미터를 추천해주는
굉장히 유용한 알고리즘입니다.
오른쪽에 보시다시피
6개의 알고리즘에 대한 추천을 해줍니다.
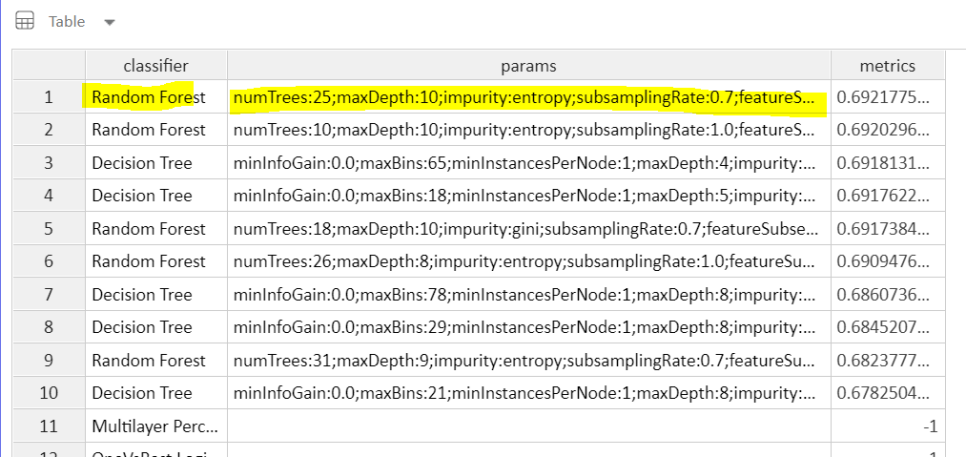
실행 결과, Random Forest 와 그에 맞는 파라미터를 추천해주는 것을 볼 수 있습니다.
굉장하죠?!
그러나
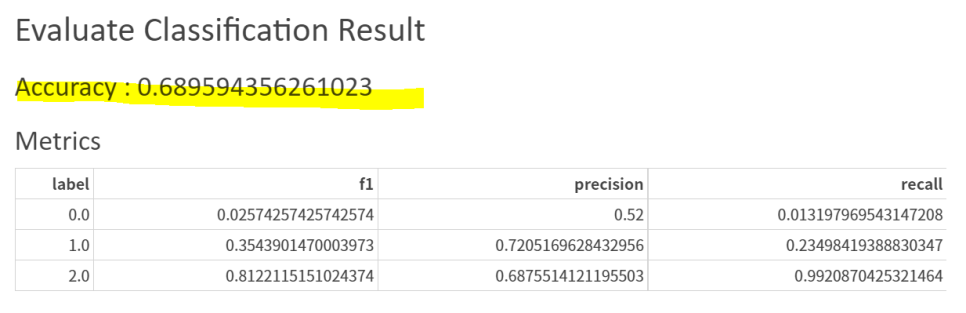
Accuracy가 높은 편은 아닙니다.
어떻게 하면 성능이 더 높게 나올지는 추가적으로 분석이 필요해보입니다.
(3) XGB Classification with 혜현's 데이터

혜현이가 전처리한 데이터를 기반으로
Column과 파라미터를 조정한 결과
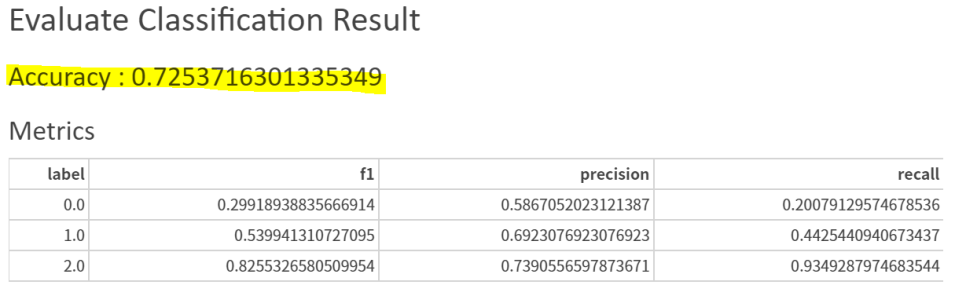
Accuracy가 0.725까지 올라갔습니다.
기존 파이썬 코드의 Accuracy인 0.7384와 거의 근접해가는 것을 볼 수 있습니다 😊😊
어떠신가요?!
Python에 비해 훨씬 쉽게 따라올 수 있으신가요?
Brightics Studio/AI를 쓰면 쓸수록 놀라운 기능들이 많다는 것을 느끼고 있습니다..!

이렇게 해서 저의 분석 프로젝트는 끝이 났고
다음 주는 팀원들이 한 분석을 기반으로 Stacking 하여 성능을 더욱 높이는 방법을 구현하고자 합니다.
다음 주도 기대해주세요 💙
* Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS #브라이틱스 #브라이틱스서포터즈 #AI #분석플랫폼 #분석프로그램 #데이터분석 #빅데이터 #인공지능 #SamsungSDS #초보자분석 #분석초보 #코딩 #코딩초보 #통계 #데이터사이언스 #Python #R #SQL #Scala #분석툴 #BrighticsAI #BrighticsStudio #브라이틱스스튜디오 #Brightics #대외활동 #대학생 #대학생대외활동 #삼성SDSBrightics #모델링
'삼성SDS Brightics' 카테고리의 다른 글
| [삼성SDS Brightics] 팀미션 2-4. 구해줘! 분석 우당탕탕 촬영기 (나 고등학생 된고야? ~(>_<。)\) (0) | 2021.08.24 |
|---|---|
| [삼성SDS Brightics] 팀미션 2-3. 청하가 부릅니다. 스태킹 Stacking~🎧 (0) | 2021.08.17 |
| [삼성SDS Brightics] 팀미션 2-1. Brightics Studio로 데이콘을 나간다고?(대금 연체 다 걸렸어~!) (0) | 2021.08.03 |
| [삼성SDS Brightics] 팀미션 1-3. <속보> [분석맨] 유튜브 올라오다.. (0) | 2021.08.03 |
| [삼성 SDS] ProDS, 필수역량이 된 데이터 분석 그리고 이를 위한 자격증 (0) | 2021.07.21 |