
안녕하세요~~!
Brightics 서포터즈 2기 정해웅입니다 💙
날씨가 선선해져서 기분이 좋은 요즘입니다 ㅎㅎ
(논문이 끝나서 기분좋은걸까요..?)
이번 포스팅부터는 본격적으로 모델링을 진행하려 했으나 어떻게 할까 구상 중에,,
먼저 테스트 데이터를 생성하는 것이 먼저일 것 같다는 생각이 불현듯 들어서
데이터 전처리!! 마지막!!!!!! 단계로 진행해보려고 합니다 ㅎㅎ
(전처리 마지막 맞겠죠..?)
제가 개인분석미션 처음 시작할 때 하고자 했던 분석을 리마인드 해보려고합니다.
2018년부터 2020년 12월까지의 채용 업종 변화에 대해 자세하게 살펴보고,
또 Brightics의 유용한 분석/예측 기능을 활용해 앞으로의 채용 트렌드를 예측하자
이렇게 당찬 포부(?)를 밝혔었는데요.
앞선 게시물들에서 자세한 EDA를 통해 2018년부터 2020년 12월까지의 채용 트렌드를 자세하게 분석했습니다.
이제 남은 것은 바로 채용 트렌드를 예측하는 것인데요.
그 전에 먼저 예측하고자 하는 데이터를 생성하고자 합니다.
어떻게 만들었나 확인해볼까요~~?
1. 예측용 테스트 데이터 생성
앞선 분석에서 볼 수 있듯이
제가 사용한 초기 데이터는 2018년 9월부터 2020년 12월까지의 채용 변화 데이터였고,
개인분석미션 3-3에서 2021년 9월 데이터를 추가한 적이 있죠.
제가 원하고자 하는 것은 추후의 채용 공고 수는 과연 어떻게 될지입니다.
즉, 2021년 9월을 넘어서 10월, 11월, 12월 그리고 2022년에는 과연 어떻게 변할지에 대한 예측입니다.
모델 학습하기에 충분한 양의 데이터를 가지고 있지 않아 얼마나 괜찮은 성능이 나올지 걱정되긴 하지만,,!!
그 추이를 예측하는 것만 해도 의의를 가질 수 있을 것 같아 진행하고자 합니다.
그 전에 테스트용 데이터셋을 만들려고 합니다.
테스트용 데이터셋에는 그렇다면 어떤 정보가 포함되어야할까요?
테스트용 데이터셋에는 산업별 그리고 세부 직종이 모두!! 포함된 데이터셋이 필요합니다.
테스트용 데이터셋에 기존 데이터에는 있는 column이 빠지게 된다면, 그 부분을 놓치기 때문입니다.
따라서 저는 기존 데이터셋에서의 산업별, 세부 직종이 모두 포함된 데이터셋을 만들려고 합니다.
테스트용 데이터셋을 만드는 과정을 살펴보려고 합니다.

기본적인 column의 형태는 기존 데이터셋과 동일하게 유지합니다.
기존 데이터셋에 있는 모든 분류(industry_detailed)를 포함한 데이터를 생성하려고 하는데,
문제는 기존 데이터셋에서 얼마나 많은 industy_detailed로 구분되어 있는지를 확인하지 않았다는 것입니다.
따라서 먼저 이를 파악하기 위해 Brightics studio의 기능을 활용해보겠습니다.
Brightics Studio의 유용한 기능 중 하나인 [String Summary] 함수 기억나시나요?
바로 문자열로 구성된 해당 column을 분석해주는 함수입니다.

이렇게 load한 데이터를 바탕으로 [String Summary] 함수에 연결해줍니다.
이후, 분석을 원하고자 하는 column을 선택합니다.
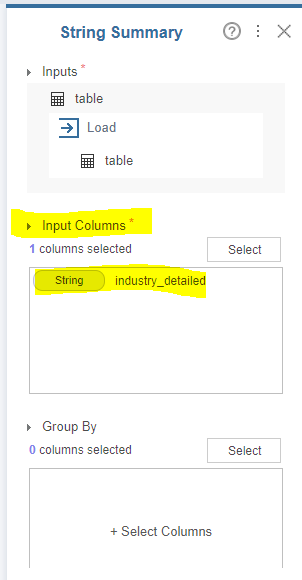
저는 industry_detailed column이 총 몇 개로 이루어져 있는지 궁금해서 함수를 실행시켜봤습니다.

num_of_distinct에서 확인할 수 있듯이
120개의 분류를 가지고 있는 것을 확인할 수 있네요.
이는 [String Summary] 뿐만 아니라 [Profile Table]과 [Label Encoder] 함수를 통해서도 확인가능한데요.
다양한 함수를 통해서 이를 직관적으로 확인할 수 있다는게 놀랍습니다,,,,
역시 Brightics Studio만의 직관성은 따라갈 플랫폼이 없는 것 같습니다 😱
간단하게 [Profile Table]을 다시 확인해보자면
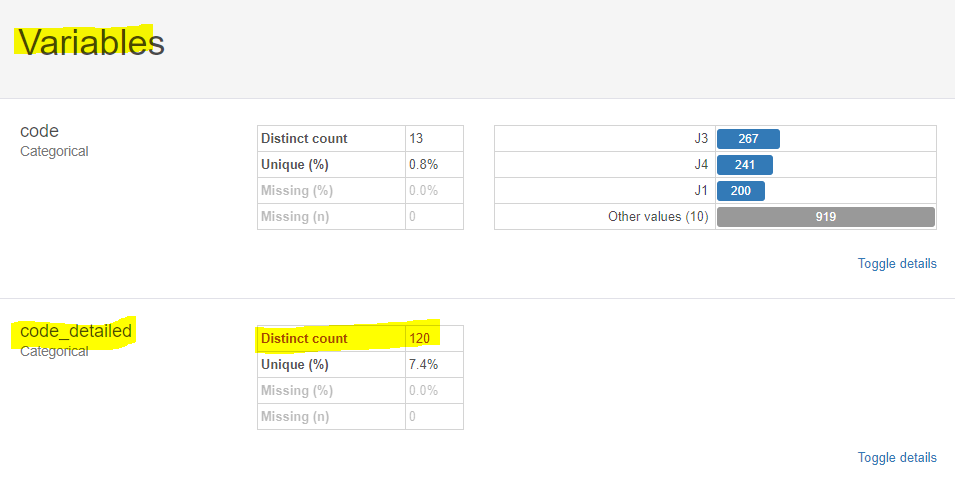
이렇게 Variables 중 code_detailed 의 Distinct count가 동일하게 120개 임을 알 수 있습니다.
그렇다면 [Label Encoder]을 마지막으로 살펴볼까요?

위 사진은 기존 데이터에 Label Encoder 함수를 실행시켜
문자열로 구성되어있던 industry_detailed 열을 일련의 숫자로 변환시킨 모습입니다.

이렇게 내림 차순으로 바꿔주면 119까지 index가 있는 것을 볼 수 있습니다.
0부터 119까지 있으니 120개 맞는 것 확인하셨죠?!
세부 직종이 120개임을 확인했다면!!
테스트용 데이터를 본격적으로 생성해보겠습니다.
먼저 저는 테스트용 csv 파일을 새로 만들었습니다.

기존 데이터에서 엑셀 정렬을 이용해서 code_detail에 대한 정렬을 진행합니다.

이후 테스트 데이터에 기존 데이터의 분류에 대한 정렬들을 꼼꼼하게 채워줍니다.

뭔가 더 편한 방법이 있을 것 같은데,,,ㅠㅜㅠㅜㅠㅜㅠㅜ
저는 잘 모르겠어서 이렇게 일일이 했습니다...
혹시라도 아신다면 댓글로 알려주세요 😂
약간의 수작업 결과,,, 120개 세부 직종을 다 채웠습니다.

index row 제외하고 120개 다 채운거 보이시나요,,
처음에 122개 나와서,, 엥? 이랬더니 몇개는 중복해서 썼더라구요.. 허허
다음으로는 월을 채워줍니다.
가장 먼저! 예측하려고 하는 10월을 채워주었습니다.
이후 산업과 산업코드를 채워줍니다.
(처음에 같이 하면 되는데.. 굳이 뒤에 하는 난 바보야..)

짜잔!!!
이렇게 해서 모든 데이터셋을 완성시켰습니다.
2. 예측용 테스트 데이터셋 Brightics studio에 Load
이제 만들어 놓은 test용 데이터셋을 Brightics Studio에 올리고자 합니다.
동일하게 Load하면 됩니다!
간략한 과정 살펴보겠습니다.
test 데이터용 Load를 새로 추가해줍니다.

이후 [Bind Row Column]이라는 함수를 통해서
두 개의 Table을 서로 합치는 과정을 진행합니다.
first_table 에 Load
second_table에 Load_test table을 넣어줍니다.
Row를 선택하여 row 아래로 추가합니다.

이렇게 2021년 10월의 데이터셋이 추가된 것을 확인할 수 있습니다.
처음에 에러가 나길래 왜그럴까 해서 보니
제가 test용 데이터에 num과 rate에 숫자를 추가 안하다보니
이 column을 str타입으로 지정되었더라구요.
이를 double 타입으로 바꿔주었습니다.
이렇게 해서 이제 모델링을 드디어!! 할 준비를 모두 마친 것 같습니다.
어떠한 모델 사용해서 예측할 지 아직 팀원들과 멘토님과 상의하며 정해야 할 것 같습니다.
그럼 환절기 몸 조심하세요 😀
* Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS #브라이틱스 #브라이틱스서포터즈 #AI #분석플랫폼 #분석프로그램 #데이터분석 #빅데이터 #인공지능 #SamsungSDS #초보자분석 #분석초보 #코딩 #코딩초보 #통계 #데이터사이언스 #Scala #분석툴 #BrighticsAI #BrighticsStudio #브라이틱스스튜디오 #Brightics #대외활동 #대학생 #대학생대외활동 #삼성SDSBrightics #중소기업은행 #중소기업채용트렌드 #중소기업채용